Power failure: why small sample size undermines the reliability of neuroscience
📄 Original study📌 Appears in:
Plain English Summary
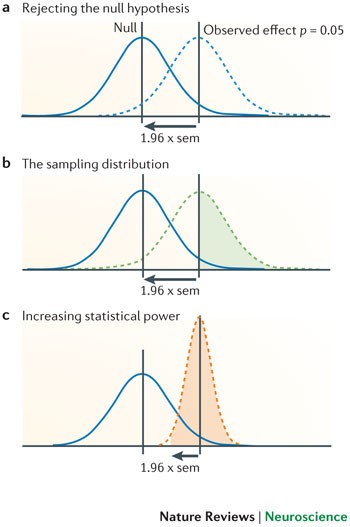
Most neuroscience studies are woefully underpowered — meaning they use too few participants to reliably detect real effects. This landmark analysis of 730 studies found the typical study had only a 21% chance of catching a true effect, dropping to a dismal 8% for brain volume research. When underpowered studies do land on significant results, those results are more likely flukes than real discoveries. The "winner's curse" inflates initial effect sizes by 25–50%, and the authors found far more significant results than expected (349 versus 254), a telltale sign of reporting bias. This matters hugely for parapsychology, where small studies dominate and meta-analyses pool many underpowered experiments. The fix? Pre-register studies, plan sample sizes in advance, share data, and run large collaborative replications.
Abstract
A study with low statistical power has a reduced chance of detecting a true effect, but it is less well appreciated that low power also reduces the likelihood that a statistically significant result reflects a true effect. Here, we show that the average statistical power of studies in the neurosciences is very low. The consequences of this include overestimates of effect size and low reproducibility of results. There are also ethical dimensions to this problem, as unreliable research is inefficient and wasteful. Improving reproducibility in neuroscience is a key priority and requires attention to well-established but often ignored methodological principles.
Links
Related Papers
Cites
Companion
- Testing for Questionable Research Practices in a Meta-Analysis: An Example from Experimental Parapsychology — Bierman, Dick J (2016)
- Editors' Introduction to the Special Section on Replicability in Psychological Science: A Crisis of Confidence? — Pashler, Harold (2012)
- A Practical Solution to the Pervasive Problems of p Values — Wagenmakers, Eric-Jan (2007)
- Mindless Statistics — Gigerenzer, Gerd (2004)
- Experimenter Fraud: What Are Appropriate Methodological Standards? — Kennedy, J.E (2017)
- Registered Reports: A Method to Increase the Credibility of Published Results — Nosek, Brian A (2014)
- Equivalence Tests: A Practical Primer for t Tests, Correlations, and Meta-Analyses — Lakens, Daniël (2017)
- The "File Drawer Problem" and Tolerance for Null Results — Rosenthal, Robert (1979)
- Small Telescopes: Detectability and the Evaluation of Replication Results — Simonsohn, Uri (2015)
Cited By
- Testing for Questionable Research Practices in a Meta-Analysis: An Example from Experimental Parapsychology — Bierman, Dick J (2016)
- The Garden of Forking Paths: Why Multiple Comparisons Can Be a Problem, Even When There Is No "Fishing Expedition" or "P-Hacking" and the Research Hypothesis Was Posited Ahead of Time — Gelman, Andrew (2013)
Also by these authors
More in Methodology
Paranormal belief, conspiracy endorsement, and positive wellbeing: a network analysis
Planning Falsifiable Confirmatory Research
Addressing Researcher Fraud: Retrospective, Real-Time, and Preventive Strategies — Including Legal Points and Data Management That Prevents Fraud
Quantum Aspects of the Brain-Mind Relationship: A Hypothesis with Supporting Evidence
Paranormal beliefs and cognitive function: A systematic review and assessment of study quality across four decades of research
📋 Cite this paper
Button, Katherine S, Ioannidis, John P.A, Mokrysz, Claire, Nosek, Brian A, Flint, Jonathan, Robinson, Emma S. J, Munafò, Marcus R (2013). Power failure: why small sample size undermines the reliability of neuroscience. Nature Reviews Neuroscience. https://doi.org/10.1038/nrn3475
@article{button_2013_power_failure,
title = {Power failure: why small sample size undermines the reliability of neuroscience},
author = {Button, Katherine S and Ioannidis, John P.A and Mokrysz, Claire and Nosek, Brian A and Flint, Jonathan and Robinson, Emma S. J and Munafò, Marcus R},
year = {2013},
journal = {Nature Reviews Neuroscience},
doi = {10.1038/nrn3475},
}